Harvard Measured Why Your Best People Managers Are Your Best Agent Managers
The same thing that makes you good at managing people makes you good at managing agents.
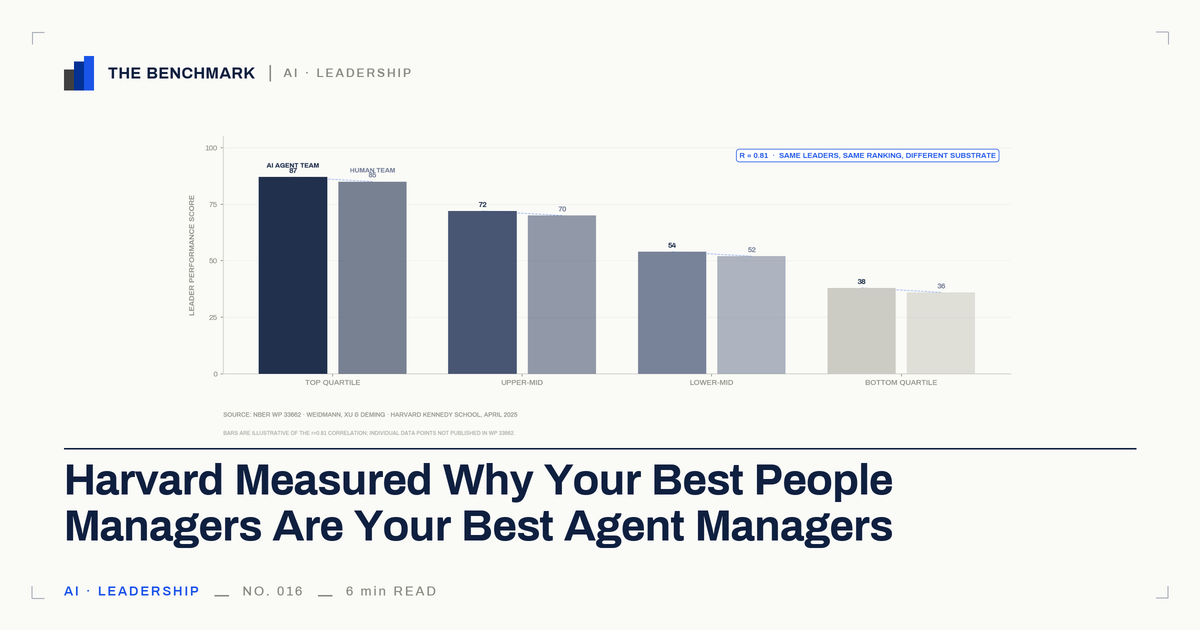
The variance isn't in the technology
Companies are pouring money into agentic AI and getting results all over the map. MIT Sloan Management Review reports 35% of organizations have already put agents into the work, with another 44% planning to. And the outcomes aren't tracking the spend. S&P Global found 42% of companies walked away from most of their AI work in 2025, up from 17% the year before.
Same models. Same vendors. Wildly different results. The question everyone is asking is why.
A pre-registered Harvard study has an answer, and it isn't about the technology.
The same people led both teams well
In April 2025, three researchers at Harvard Kennedy School published NBER Working Paper 33662. The design was clean. They had people lead teams of AI agents on problem-solving tasks. Then they randomly reassigned those same people to lead teams of humans on the same kind of work, and ran it again. Random reassignment matters — it rules out the result being a fluke of who got paired with whom. The same person was measured leading both kinds of teams.
How well someone led the agents predicted how well they led the humans at r=0.81. That is most of the way to a perfect match. The people who got the most out of the agents were, with little exception, the same people who got the most out of the humans.
The obvious objection is that this is just raw smarts — the sharp people win in any room. So the researchers stripped that out, controlling for task-specific cognitive ability. The link held at r=0.69. Something other than being clever is carrying the result.
So they looked at what the strong leaders actually did differently. Three behaviors separated them, and each one is concrete enough to watch for.
They asked more questions. Instead of issuing the task and walking away, the strong leaders probed — what's missing, what would you check, what does this assume. With agents, that looks like interrogating the output instead of accepting the first pass.
They went back and forth more. The work moved in turns rather than one long instruction followed by silence. Define, see what comes back, respond to it, refine. The conversation had a rhythm, and the rhythm was shared by both leader and team.
And they used more language that pulled the team in — plural, inclusive, "we" and "us" rather than a list of orders. It framed the work as a shared problem, not a handoff.
One more finding is worth holding onto. Word count alone didn't predict anything. The leaders who won weren't the ones who typed the most. Structure and tone did the work — how the task got framed, not how much got said.
Managing agents turns out to be managing
The thing that makes someone good with a team of people is the thing that made them good with a team of agents. Same skill, measured in both rooms, producing the same lift.
It's the work you already know. Say what the task is. Set the edges. Watch what comes back. Fix what drifts. Give room to work. That's not a new discipline for the agentic era — it's what good management has always been, and the study found it carries over with almost nothing lost on the way.
Read it backwards and it's just as true. The leader who tosses a vague brief over the wall and never looks at the result gets thin work out of people, and gets thin work out of agents for the same reason: nobody defined what good looked like, and nobody checked. The failure mode ports over as cleanly as the strength does.
This isn't only the Harvard team's read. California Management Review reached the same place from a different direction, concluding that "managing a multi-agent system resembles managing a multi-disciplinary team of professionals." Two independent lines of work, lab and analytical, landing on one finding: it's the same job.
Your agents are a daily read on how you lead
That reframes what an agentic deployment gives you.
A human team is slow to read. You set someone up to lead it, and it takes a quarter or two of one-on-ones, review cycles, and skip-levels before you can tell how it's going. The signal is real but it arrives late, and it's tangled up in everything else moving through the org.
An agentic deployment is fast. It produces output you can see this afternoon — no review cycle, no calendar, no politics, just the work, every day, in plain view. The same management skill that takes two quarters to read on a human team shows up in the agent output by Thursday. The handoff that was too loose, the task that was never really defined, the correction nobody sent — it's all sitting right there in what the agents returned.
That's a live read on how the work is being led, available daily, that the human side can't give you nearly that fast.
It also reframes the abandonment wave. Remember the 42% who walked away from most of their AI work in 2025, up from 17%. The standard story blames the technology — the model wasn't ready, the use case was wrong. The Harvard data says a large share of that variance was never in the stack. It was in how the work got handed off. Some of those abandoned projects didn't have a model problem. They had the same handoff problem that produces thin work from people, showing up faster and more visibly because the agents surface it within days.
Where this argument gets complicated
There's a real counter, and it's worth stating in full.
Everything we know about managing people says give the team more room as it matures. McKinsey argues the opposite for agents: constrain them tighter early, stay more hands-on, keep the edges narrow at the start. If the central move of good management runs in opposite directions depending on the team, the "same skill" claim looks like it has a hole.
It holds, and here's why. The skill was never "give more room" or "give less room." The skill is reading where the team actually is and setting the room to match. You don't hand a new hire the latitude you give a five-year veteran. You don't hand an untested workflow the latitude you give one you've watched run clean for six months. Which way you adjust depends on what's in front of you. The act of adjusting to it is the constant, and that's the part that ported across both teams in the study.
There's a harder edge worth naming, and it's where the argument stops holding. At enterprise scale, when agents produce faster than anyone can check the work, the loop breaks. Two researchers documented it in January 2026 and called it the responsibility vacuum: past a certain volume, checking the output stops being a real decision and becomes rubber-stamping. At that point the connection between leadership and output gets hard to read — not because leadership stopped mattering, but because no one can see what the agents are doing anymore.
That's a scale problem, not a function problem. Run a single function and the loop is still close enough to read every day. The finding applies cleanly where most of this work is actually happening — inside one team, one function, one deployment a person can still see. It's the company-wide, thousand-agent sprawl where the read gets lost, and that's not where most of this is being decided right now.
Bottom Line
The Harvard data points at one variable above the others: leadership quality, not model quality, is the biggest predictor of what an agentic team produces. A one-step improvement in the leader bought the same lift whether the team was people or agents.
So when the agents come back with noise and the model is fine, the move isn't another tool. It's the management skill of the people running them — the ability to define the task, set the expectation, read what comes back, and send a real correction.
That's the same skill that makes those people better with the humans they manage. So the research suggests one investment, not two: develop that skill, and both teams improve at once. When agentic results are uneven across your function, that's where to put the effort.
Sources
- National Bureau of Economic Research — NBER Working Paper 33662, Weidmann, Xu & Deming, April 2025
- MIT Sloan Management Review — The Emerging Agentic Enterprise, November 2025
- S&P Global Market Intelligence — AI Experiences Rapid Adoption but with Mixed Outcomes, 2025
- California Management Review — Rethinking AI Agents: A Principal-Agent Perspective, Jarrahi & Ritala, July 2025
- McKinsey & Company — Six Shifts to Build the Agentic Organization of the Future
- arXiv — The Responsibility Vacuum in Enterprise Agentic Systems, Romanchuk & Bondar, January 2026