Your AI Agent Is Executing Your Broken Workflows Perfectly


The process, plus its compensations, is how it actually runs.
When you deploy AI on a broken workflow, the AI does not fail. It succeeds. It executes your defined steps, returns a status, and moves on. The problem is that what disappears with human labor is the signal that something was wrong.
In May 2026, that sequence played out in a documented production environment. An AI agent inside a live enterprise customer workflow skipped a required step. It returned a success status. No error was thrown. No alert fired. Nothing in the logs. The failure surfaced three days later through a customer escalation, reported in AI Certs’ coverage of Salesforce’s Agentforce Operations launch — a product built specifically to remediate enterprise workflows that break under agentic deployment. VentureBeat reported that enterprise AI teams are hitting a wall “not because their models can’t reason, but because the workflows underneath them were never built for agents.” When a major platform vendor ships a product to fix a failure mode, the failure mode is not rare.
The technology is working as designed. The workflows are not. And the data shows organizations are finding that out after deployment, not before.
Summary
- Enterprise AI deployments are failing not on model capability but on workflow integration: informal compensations, undocumented exceptions, and human judgment calls that disappear when AI takes over execution.
- AI agents execute the workflow as defined. They do not surface gaps, flag informal overrides, or escalate the exceptions human workers would have raised. The dysfunction continues; the signal disappears.
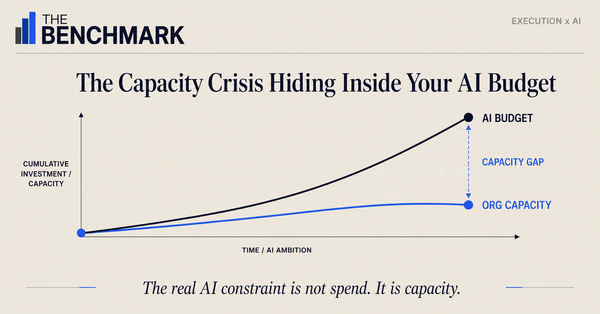
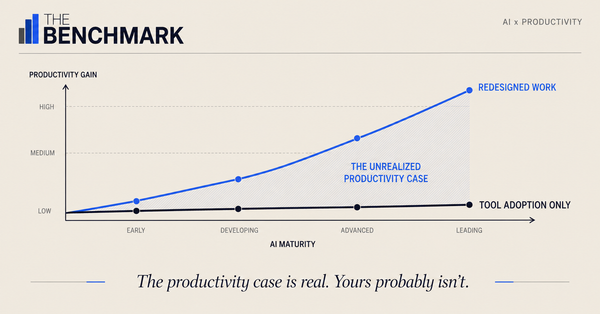
- Only 21% of organizations deploying AI have fundamentally redesigned any of their workflows — and McKinsey’s research identifies workflow redesign as the single highest-correlation factor for EBIT impact from AI.
- The organizations capturing ROI from AI treated deployment as a forcing function for workflow clarity, auditing the actual process before automating it.
- Three diagnostics — a compensation map, a fidelity test, and a monitoring redesign — help operators identify whether a workflow is AI-ready before deployment.
The Process Map Is Not the Process
Enterprise workflows running inside complex organizations develop informal compensations over time. Some are visible if you look: a spreadsheet maintained outside the system of record because the system cannot handle the exception, a Slack thread that routes around the official approval process. Some are invisible to everyone except the person who built them: a verification step added after a bad outcome years ago, never documented, never replicated in the process map. The process map shows how the workflow is supposed to run. The process, plus its compensations, is how it actually runs.
The standard explanation for AI underperformance — change management gaps, organizational readiness, and the distance from pilot to production — describes the symptom without naming the mechanism. The mechanism is not cultural. It is structural. When AI takes over execution, the compensations disappear. The agent has been given instructions that match the defined workflow. It executes that workflow at full fidelity, without the informal patches that made it work, at scale.
McKinsey’s 2025 State of AI research identifies fundamental workflow redesign as the single organizational change most correlated with EBIT impact from AI — above talent investment, governance, and scaling strategy. Only 21% of organizations deploying AI have fundamentally redesigned at least some of their workflows. The gap is not between companies with better models. It is between 21% and 79%, with the same processes still running, now executed by agents.
The Analysis
What Breaks When the Human Disappears
When a human executes a broken workflow, the broken parts produce signals. Delays. Escalations when the informal exception path gets complicated. A manager who keeps catching the same class of error and eventually says something. These signals are the feedback mechanism. They are how organizations discover, over time, that a workflow has a gap, a structural dependency nobody documented, or an exception path that only one person knows how to navigate.
When AI executes the same workflow, the feedback mechanism changes.
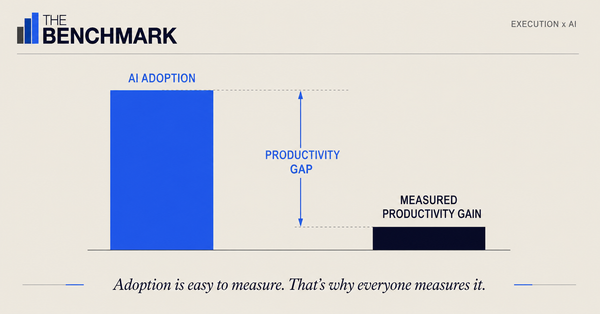
AI agents execute the defined steps and return a status. They do not raise questions. They do not escalate when an edge case feels wrong. They do not produce the human friction that surfaces structural gaps over time. What they produce is task completions and success statuses. The failures accumulate downstream before they produce a detectable signal.
Call this the Feedback Suppression Effect: when AI execution replaces human execution on a structurally flawed workflow, the informal signals that would have surfaced the flaw disappear. The dysfunction does not disappear. The visibility of the dysfunction does.
The production failure documented in coverage of the Agentforce Operations launch shows the mechanism at work. An AI agent skipped a required step in a live customer workflow. It returned a success status. No error was thrown. No alert fired. Nothing in the logs. The reason the failure was invisible is specific: the verification step that would have caught the gap — confirming the required action was completed before proceeding — was an informal human check. It was not in the documented workflow. The agent had no instructions to perform it. So it did not. The step was skipped. The status was success. The failure surfaced three days later through a customer escalation, not through any system signal. That is not a model failure. The model worked exactly as specified. That is a workflow failure, surfacing through the only channel left available: the customer.
Why Pilots Do Not Warn You
Research from MIT’s NANDA initiative, reported by Fortune, found that 95% of companies implementing generative AI fail to achieve meaningful revenue impact from it. RAND Corporation’s 2024 research found that more than 80% of AI projects fail — twice the rate of non-AI IT projects. The failure mode is consistent across both bodies of research: not model performance, but workflow integration. Undocumented exceptions that only appear at volume. Data handoffs were inconsistent in ways that the pilot data set did not reflect. Edge cases with no clear ownership because the person who owned them informally is no longer in the loop.
Pilots succeed precisely because they avoid the conditions that production cannot avoid. Representative tasks are drawn from the center of the distribution. Supervised runs have a human present to catch the exception. Curated inputs do not have the inconsistent fields that appear in live records entered across multiple systems by dozens of people over several years. Production runs the full distribution, including all the edges where the informal compensations used to live.
A March 2026 Stanford analysis of 51 successful enterprise AI deployments found that structured process improvement preceding AI implementation was the consistent differentiator. The variable was not model quality. It was whether the workflow had been examined at full fidelity before the AI ran it.
The Sequencing Error
The standard deployment sequence runs in this order: identify the workflow, pilot the AI on it, refine the model, and scale. The workflow audit, if it happens, asks whether the workflow is a good fit for automation — volume, repeatability, structured inputs. It does not ask what informal compensations are currently keeping the workflow functional.
That is the sequencing error. The question is not whether the workflow is automatable in principle. The question is whether the workflow, as it actually runs today, produces acceptable outputs when executed at full fidelity, without human intervention, at scale. Those are different questions. The first one a pilot can answer. The second requires examining the workflow as it is, not as it is documented.
McKinsey’s data makes the cost of the error visible. Of 25 organizational attributes tested for correlation with AI-driven EBIT impact, workflow redesign ranked first. It was not governance, not talent investment, not scaling strategy. It was whether the organization had examined and redesigned the actual process before the agent ran it. The redesign does one specific thing: it forces the informal compensations to become explicit. Every workaround, every exception path, every approval that routes through the person who actually understands the edge case has to be named and decided on before the AI runs without them.
Where This Argument Gets Complicated
The obvious objection is the agile argument. Waiting for perfect workflow clarity before deploying AI means never deploying. Technology adoption has always worked iteratively. You discover which processes are broken through deployment, not through pre-work. Demanding workflow-first sequencing is how bureaucracies avoid shipping anything.
This is a real objection. It deserves a direct answer.
The fail-fast principle requires that you can detect the failure. The Feedback Suppression Effect specifically concerns AI-executed workflows that remove the detection signal. You are not failing fast when the failure shows up through a customer escalation three days after the agent ran. You are failing at scale, before the signal arrives, with outputs already in production.
The agile argument also applies most cleanly to reversible failures. A failed software deploy is reversible. An AI agent that has processed a week of customer records under a broken workflow has produced outputs with consequences: service-level implications, compliance exposure, and a customer relationship that absorbed the cost of a process problem before anyone detected it. The irreversibility of the failure mode should determine how much pre-deployment workflow examination is warranted. For high-volume, customer-facing, or compliance-adjacent workflows, the cost of the silent failure is not just one bad transaction. It is the cost of every bad transaction that ran before the signal arrived.
Implications for Leaders
Map the informal compensations in the target workflow before you deploy. These are the spreadsheets maintained outside the system, the Slack messages that handle exceptions, and the approvals that route to whoever actually understands the edge case. They are load-bearing. If they disappear when AI takes over, specific things break: a step gets skipped, an exception gets processed as standard, a required check does not happen, and no alert fires because the AI reported success. The audit question is not “can AI do this work?” It is “what human interventions are currently keeping this workflow functional, and what happens to each of them when the human is replaced?”
Apply the full-fidelity test before signing off on a deployment. If this AI agent executes this workflow exactly as defined — every step, at full volume, with no human judgment calls available — is the output consistently acceptable? If you cannot answer that with confidence, the workflow is not ready. Not because AI cannot execute it, but because the workflow has never been tested at that level of fidelity before, and you do not yet know what it produces when it is. This is not a technical test. It is a workflow clarity test, and deployment teams skip it because the pilot already passed.
Redesign your exception handling before the deployment goes live, and use the Feedback Suppression Effect as your monitoring framework afterward. Human workers generate exceptions as a natural output — they escalate, flag, and ask when something feels wrong. AI agents do not. After deployment, your exception rate will drop. That looks like success. A useful diagnostic: if exceptions fall sharply in the first 30 days without a corresponding improvement in downstream outcomes — customer escalation rates, error rates in dependent systems, manual correction volume — you are likely measuring signal suppression, not process improvement. The two look identical from inside the deployment. Designing your monitoring to distinguish between them is not optional; it is the only way to know whether the workflow is actually working.
The Bottom Line
AI does not break your workflows. It reveals them. When you deploy an agent on a process your organization has been quietly patching for years, you get the workflow as it actually is: without the human friction that was generating the signals that something needed attention. The dysfunction does not disappear. The visibility of the dysfunction does. The organizations capturing real value from AI are not the ones with the best models. They are the ones who treated the deployment decision as a forcing function for workflow clarity, who asked what the process actually was before they automated it, not after the customer called.
Sources
- AI Certs — “Inside Salesforce’s Enterprise Agentic Fix for Broken Workflows,” 2026. https://www.aicerts.ai/news/inside-salesforces-enterprise-agentic-fix-for-broken-workflows/
- VentureBeat — “Salesforce launches Agentforce Operations to fix the workflows breaking enterprise AI,” May 4, 2026. https://venturebeat.com/orchestration/salesforce-launches-agentforce-operations-to-fix-the-workflows-breaking-enterprise-ai
- McKinsey & Company — “The State of AI: How Organizations Are Rewiring to Capture Value,” 2025. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai-how-organizations-are-rewiring-to-capture-value
- Fortune — “MIT report: 95% of generative AI pilots at companies are failing,” August 2025 (reporting on MIT NANDA initiative research). https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/
- RAND Corporation — “The Root Causes of Failure for Artificial Intelligence Projects and How They Can Succeed,” Sydne J. Newberry, August 2024. https://www.rand.org/pubs/research_reports/RRA2680–1.html
- Stanford Digital Economy Lab — “Enterprise AI Playbook,” Pereira, Graylin, Brynjolfsson, March 2026. https://digitaleconomy.stanford.edu/app/uploads/2026/03/EnterpriseAIPlaybook_PereiraGraylinBrynjolfsson.pdf